Automatically detect problem links in your project.
Preface
Open source projects that I maintain Thanks-Mirror Collated and recorded various package managers, system images, and useful images of common software, as the project became more and more perfect, to today, has accumulated 1091 links, over time, some domestic mirrors may stop maintenance, how to customize the perception of those links that have failed, is a matter to consider.
This article introduces an interesting little action, its main function is to automatically scan the links in the repository, and then request the links, according to the custom rules, automatically throw abnormal links, and then create these links into the issue.
Disposition
Used Actions:lycheeverse/lychee-action The use of configuration is actually very simple, basically after reading the official introduction document can be used to use, but the official document introduction method is not very flexible, the official is with the help of its open source project:lycheeTo complete the check, this article will extend the configuration file for this open source project to achieve richer capabilities.
Start by adding the Actions profile,e.g. .github/workflows/links-check.yml:
name: 🔗 检查链接
on:
repository_dispatch:
push:
branches:
- main
workflow_dispatch:
schedule:
- cron: "00 18 * * *"
jobs:
linkChecker:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Link Checker
id: lychee
uses: lycheeverse/lychee-action@v1.5.1
env:
GITHUB_TOKEN: ${{secrets.GITHUB_TOKEN}}
with:
# Check all markdown and html files in repo (default)
args: --config ./.github/config/lychee.toml README.md
# Use json as output format (instead of markdown)
format: markdown
# Use different output file path
output: ./lychee/out.md
- name: Create Issue From File
if: steps.lychee.outputs.exit_code != 0
uses: peter-evans/create-issue-from-file@v3
with:
title: 🔗 链接检查报告
content-filepath: ./lychee/out.md
labels: report, automated issueBriefly introduce this action: when there is a content submission, and it will automatically run at 18 o'clock every day (of course, you can also run it manually), automatically detect all links in the
README.mdfile, use the configuration file./.github/config/lychee.toml, the result is output to./lychee/out.md, the output format is Markdown, if all the checks pass, there will be no action, if the check fails, An issue will be created automatically.
The above content mentions .github/config/lychee.toml, and here is a list of the configuration files I used:
############################# Display #############################
# Verbose program output
verbose = true
# Show progress
progress = true
# Path to summary output file.
# output = "report.md"
############################# Cache ###############################
# Enable link caching. This can be helpful to avoid checking the same links on
# multiple runs.
cache = true
############################# Runtime #############################
# Number of threads to utilize.
# Defaults to number of cores available to the system if omitted.
threads = 6
# Maximum number of allowed redirects [default: 10]
max_redirects = 10
# Maximum number of concurrent network requests [default: 128]
max_concurrency = 30
############################# Requests ############################
# User agent to send with each request
user_agent = "curl/7.83.1"
# Website timeout from connect to response finished
timeout = 10
# Minimum wait time in seconds between retries of failed requests.
retry_wait_time = 2
# Comma-separated list of accepted status codes for valid links.
# Omit to accept all response types.
#accept = "text/html"
# Proceed for server connections considered insecure (invalid TLS)
insecure = true
# Comma-separated list of accepted status codes for valid links.
# Don't work as of yet until https://github.com/lycheeverse/lychee/issues/644
# is resolved
accept = [200,204,301,429,403]
# Only test links with the given scheme (e.g. https)
# Omit to check links with any scheme
#scheme = "https"
# Request method
method = "get"
# Custom request headers
headers = []
############################# Exclusions ##########################
# Exclude URLs from checking (supports regex)
# balena base images account for ~1400 request to GitHub, they are
# omitted to avoid being rate limited.
# See https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting
# The openvpn link is omitted as trying to auto chek it results in
# a 503, even when it is available.
# The meta-balena link is included in parameterized scripts and as
# a result will always produce a failing link.
# The myorg/myapp link is a dummy address used in an example contract so is omitted.
# The balena/resin API urls will not respond to unauthenticated requests
# The gstatic and googleapis links go 404 and are excluded ever since we started checking HTML
# balenaCLI linux binary URLs always error out since they are generated on run time only
# File URLs are excluded as they aren't checked properly and error out
exclude = [
"developer.aliyun.com/*",
"mirrors.ustc.edu.cn/*",
"eryajf.net/*",
"rsproxy.cn/*",
"https://mirrors.cloud.tencent.com/go/",
"http://maven.aliyun.com/nexus/content/groups/public/",
"https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git",
"https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git",
]
# Exclude URLs contained in a file from checking
exclude_file = []
include = []
include_verbatim = true
# Exclude all private IPs from checking
# Equivalent to setting `exclude_private`, `exclude_link_local`, and `exclude_loopback` to true
exclude_all_private = true
# # Exclude private IP address ranges from checking
# exclude_private = false
# # Exclude link-local IP address range from checking
# exclude_link_local = false
# # Exclude loopback IP address range and localhost from checking
# exclude_loopback = false
# Exclude all mail addresses from checking
exclude_mail = trueMost of these contents are generic, and the two things that may need to be adjusted are: accept and exclude, when I first checked, I found that all developer.aliyun.com access in GitHub Actions was a network failure, guessing that ali restricted external access, which is understandable, so I added the entire domain name to the exclusion.
In short, checking the results requires some filtering analysis yourself, and then adjusting it in combination with the meaning of the configuration file.
PR automatic checking
If the action above does not check the PR, you can also add another action specifically to detect the link submitted by the PR:
$ cat link-check-pr.yml
name: Links (Fail Fast)
on:
pull_request:
jobs:
linkChecker:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Link Checker
uses: lycheeverse/lychee-action@v1.5.1
with:
# Check all markdown and html files in repo (default)
args: --config ./.github/config/lychee.toml README.md
# Use json as output format (instead of markdown)
format: markdown
# Use different output file path
output: ./lychee/out.md
# Fail action on broken links
fail: true
env:
GITHUB_TOKEN: ${{secrets.GITHUB_TOKEN}}In this way, when there are abnormal links during PR, the detection will fail, and some links that may be bad will be merged into the project.
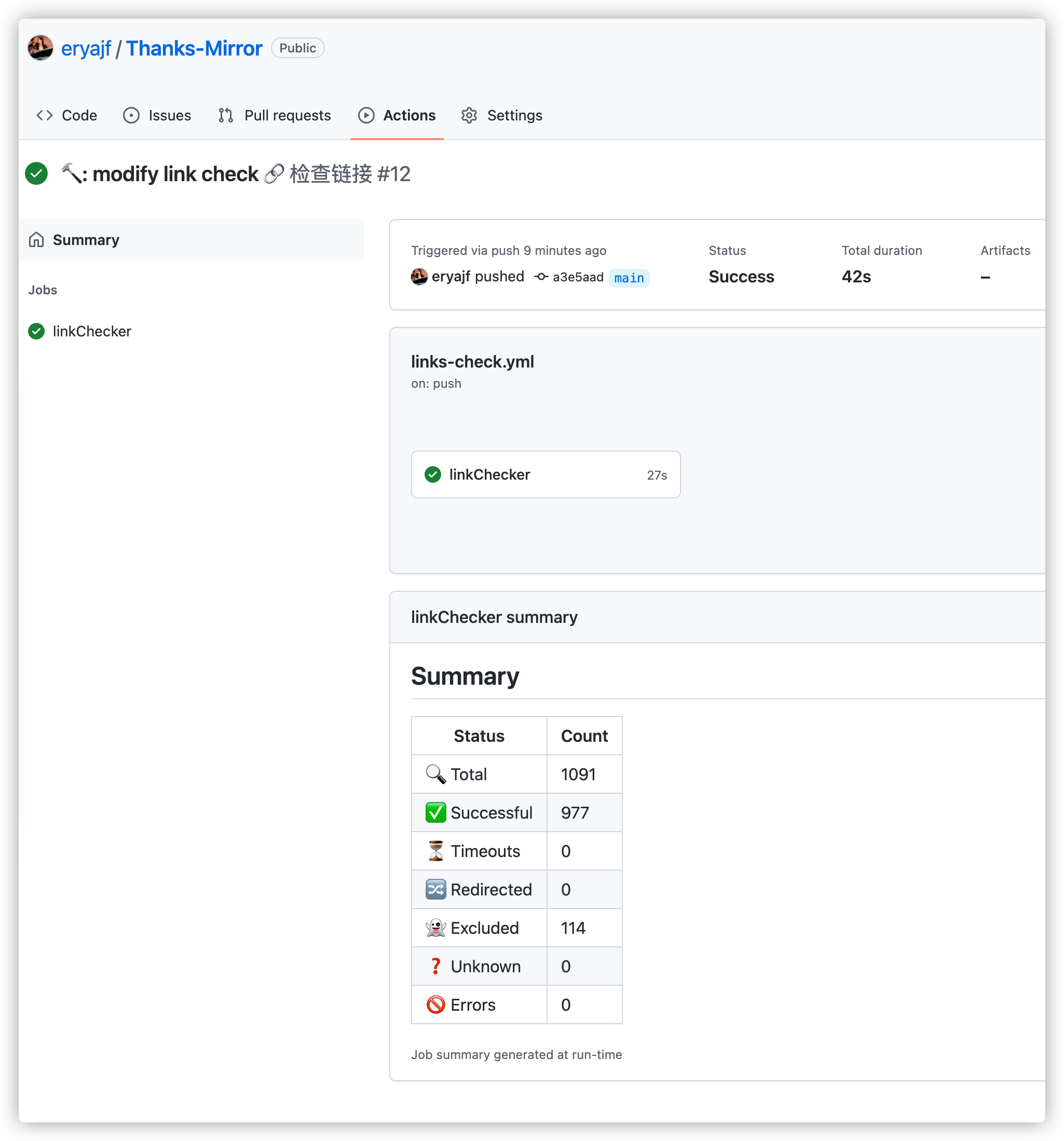
Effect
The effect after passing the test is as follows: